Accumulo 2.x Documentation >> Getting started >> Design
Design
Edit this pageBackground
The design of Apache Accumulo is inspired by Google’s BigTable paper.
Data Model
Accumulo provides a richer data model than simple key-value stores, but is not a fully relational database. Data is represented as key-value pairs, where the key and value are comprised of the following elements:

All elements of the Key and the Value are represented as byte arrays except for Timestamp, which is a Long. Accumulo sorts keys by element and lexicographically in ascending order. Timestamps are sorted in descending order so that later versions of the same Key appear first in a sequential scan. Tables consist of a set of sorted key-value pairs.
Architecture
Accumulo is a distributed data storage and retrieval system and as such consists of several architectural components, some of which run on many individual servers. Much of the work Accumulo does involves maintaining certain properties of the data, such as organization, availability, and integrity, across many commodity-class machines.
Components
An instance of Accumulo includes many TabletServers, one Garbage Collector process, one Manager server and many Clients.
Tablet Server
The TabletServer manages some subset of all the tablets (partitions of tables). This includes receiving writes from clients, persisting writes to a write-ahead log, sorting new key-value pairs in memory, periodically flushing sorted key-value pairs to new files in HDFS, and responding to reads from clients, forming a sorted merge view of all keys and values from all the files it has created and the sorted in-memory store.
TabletServers also perform recovery of a tablet that was previously on a server that failed, reapplying any writes found in the write-ahead log to the tablet.
Garbage Collector
Accumulo processes will share files stored in HDFS. Periodically, the Garbage Collector will identify files that are no longer needed by any process, and delete them. Multiple garbage collectors can be run to provide hot-standby support. They will perform leader election among themselves to choose a single active instance.
Manager
The Accumulo Manager is responsible for detecting and responding to TabletServer failure. It tries to balance the load across TabletServer by assigning tablets carefully and instructing TabletServers to unload tablets when necessary. The Manager ensures all tablets are assigned to one TabletServer each, and handles table creation, alteration, and deletion requests from clients. The Manager also coordinates startup, graceful shutdown and recovery of changes in write-ahead logs when Tablet servers fail.
Multiple managers may be run. The managers will choose among themselves a single manager, and the others will become backups if the manager should fail.
Tracer
The Accumulo Tracer process supports the distributed timing API provided by Accumulo. One to many of these processes can be run on a cluster which will write the timing information to a given Accumulo table for future reference. See the tracing documentation for more information.
Monitor
The Accumulo Monitor is a web application that provides a wealth of information about the state of an instance. The Monitor shows graphs and tables which contain information about read/write rates, cache hit/miss rates, and Accumulo table information such as scan rate and active/queued compactions. Additionally, the Monitor should always be the first point of entry when attempting to debug an Accumulo problem as it will show high-level problems in addition to aggregated errors from all nodes in the cluster. See the Accumulo monitor documentation for more information.
Multiple Monitors can be run to provide hot-standby support in the face of failure. Due to the forwarding of logs from remote hosts to the Monitor, only one Monitor process should be active at one time. Leader election will be performed internally to choose the active Monitor.
Compactor (experimental)
The Accumulo Compactor process is an optional application that can be used to run compactions outside of the TabletServer. One to many Compactors can be run on a cluster and each Compactor process performs one compaction at a time. The Compactor registers its existence in ZooKeeper and communicates with the Compaction Coordinator to retrieve its work and to register the completion status of the compaction. The Compactor process will continue to perform compactions in situations where normal in-TabletServer compactions would fail, such as TabletServer restart and Tablet re-hosting.
Compaction Coordinator (experimental)
The Accumulo Compaction Coordinator is an optional application that is required to run compactions outside of the TabletServer. The Coordinator is responsible for communicating with the TabletServers, to identify what external compaction work needs to be done, and the Compactors to assign work, get status updates, and cancel running external compactions.
Multiple Coordinators may be run. The Coordinators will choose among themselves a single active Coordinator, and the others will become backups if the active Coordinator should fail.
Scan Server (experimental)
The Accumulo Scan Server is an optional application that can be used to run scans on a tablet’s data outside of the Tablet Server. Many Scan Servers can be run on a cluster and each Scan Server may run one or more scans concurrently (dependent on configuration). Scans running in a Scan Server do not have to be concerned about tablet re-hosting or contention with ingest, compactions, and other tablet maintenance activities. The trade-off when using Scan Server’s is that the tablet hosted within the ScanServer may not contain the exact same data as the corresponding tablet hosted by the Tablet Server. The Scan Server does not have any of the Tablet data that may reside within the in-memory maps and the tablet may reference files that have been compacted as tablet metadata can be cached within the Scan Server (See Scan Server configuration properties).
Client
Accumulo has a client library that can be used to write applications that write and read data to/from Accumulo. See the Accumulo clients documentation for more information.
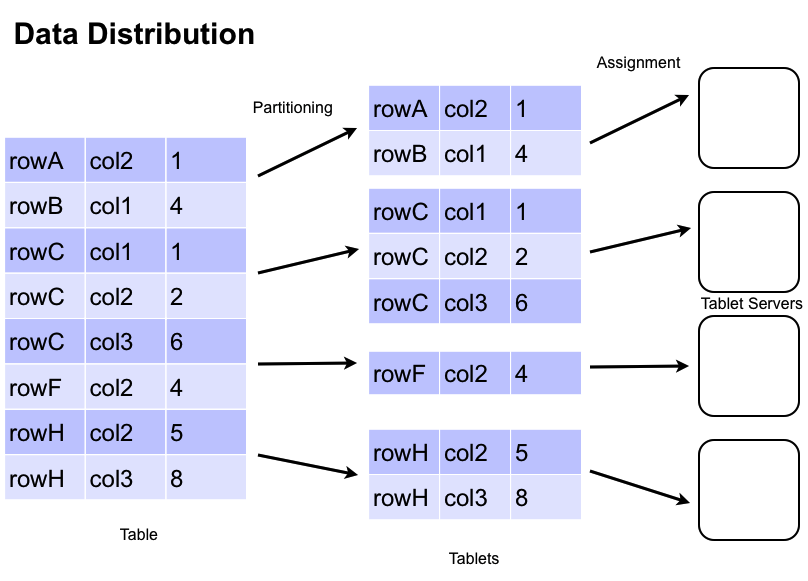
Data Management
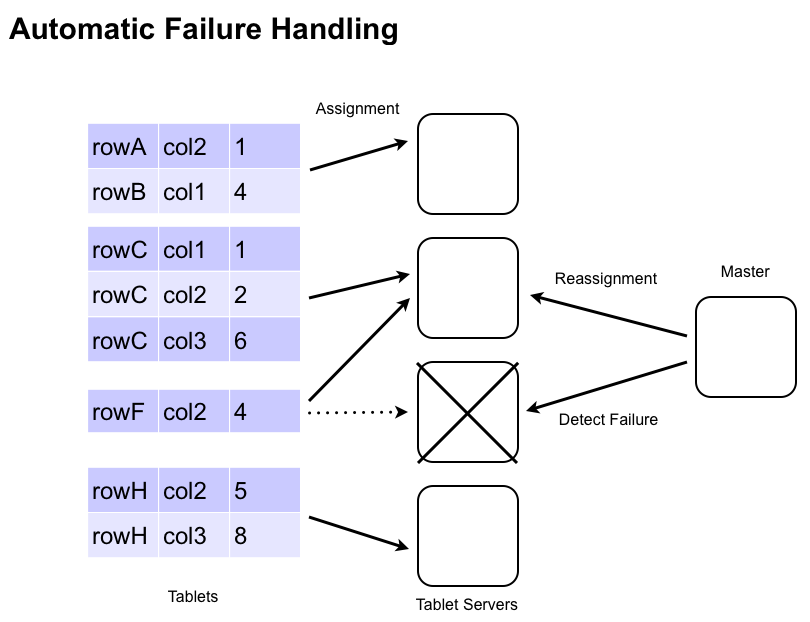
Accumulo stores data in tables, which are partitioned into tablets. Tablets are partitioned on row boundaries so that all of the columns and values for a particular row are found together within the same tablet. The Manager assigns Tablets to one TabletServer at a time. This enables row-level transactions to take place without using distributed locking or some other complicated synchronization mechanism. As clients insert and query data, and as machines are added and removed from the cluster, the Manager migrates tablets to ensure they remain available and that the ingest and query load is balanced across the cluster.
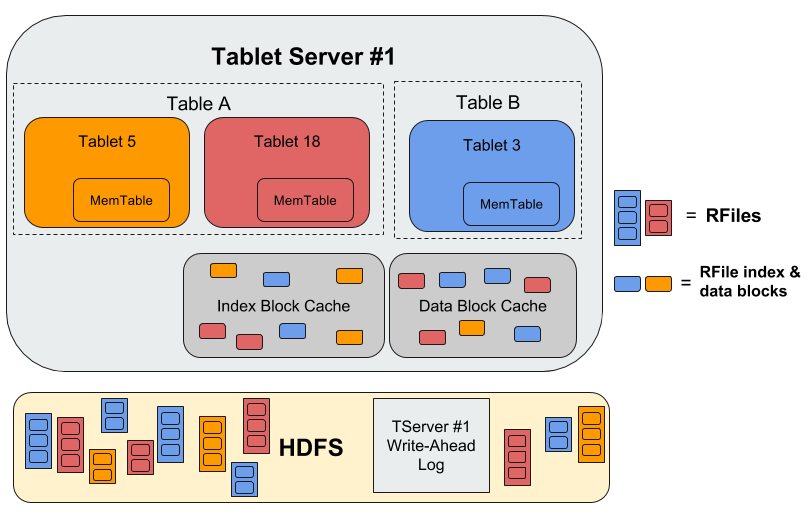
Tablet Server
When a write arrives at a TabletServer it is written to a Write-Ahead Log and then inserted into a sorted data structure in memory called a MemTable. When the MemTable reaches a certain size, the TabletServer writes out the sorted key-value pairs to a file in HDFS called an RFile. This process is called a minor compaction. A new MemTable is then created and the fact of the compaction is recorded in the Write-Ahead Log.
When a request to read data arrives at a TabletServer, the TabletServer does a binary search across the MemTable as well as the index blocks associated with each RFile to find the relevant values. If clients are performing a scan, several key-value pairs are returned to the client in order from the MemTable and data blocks of RFiles by performing a sorted merge as they are read. If caching is enabled for the table, any index or data block is stored in the block cache to speed up future scans.
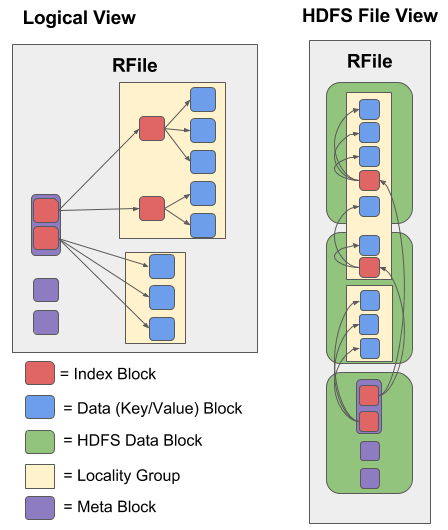
RFile
RFile (short for Relative Key File) is a file that contains Accumulo’s sorted key-value pairs. The file is written to HDFS by Tablet Servers during a minor compaction. RFiles are organized using the Index Sequential Access Method (ISAM). RFiles consist of data (key/value) block, index blocks (which are used to find data block), and meta blocks (which contain metadata for bloom filters and summary statistics). Data in an RFile is separated by locality group. The diagram below shows the logical view and HDFS file view of an RFile.
Compactions
In order to manage the number of files per tablet, periodically the TabletServer performs Major Compactions of files within a tablet, in which some set of RFiles are combined into one file. The previous files will eventually be removed by the Garbage Collector. This also provides an opportunity to permanently remove deleted key-value pairs by omitting key-value pairs suppressed by a delete entry when the new file is created. See the compaction documentation for more information.
Splitting
When a table is created it has one tablet. As the table grows its initial tablet eventually splits into two tablets. It’s likely that one of these tablets will migrate to another tablet server. As the table continues to grow, its tablets will continue to split and be migrated. The decision to automatically split a tablet is based on the size of a tablets files. The size threshold at which a tablet splits is configurable per table. In addition to automatic splitting, a user can manually add split points to a table to create new tablets. Manually splitting a new table can parallelize reads and writes giving better initial performance without waiting for automatic splitting.
As data is deleted from a table, tablets may shrink. Over time this can lead to small or empty tablets. To deal with this, the merging of tablets was introduced in Accumulo 1.4.
Fault-Tolerance
If a TabletServer fails, the Manager detects it and automatically reassigns the tablets assigned from the failed server to other servers. Any key-value pairs that were in memory at the time the TabletServer fails are automatically reapplied from the Write-Ahead Log(WAL) to prevent any loss of data.
Tablet servers write their WALs directly to HDFS so the logs are available to all tablet servers for recovery. To make the recovery process efficient, the updates within a log are grouped by tablet. TabletServers can quickly apply the mutations from the sorted logs that are destined for the tablets they have now been assigned.
TabletServer failures are noted on the Manager’s monitor page, accessible via
http://manager-address:9995/monitor.