External Compactions
Author: Dave Marion, Keith Turner
Date: 08 Jul 2021
External compactions are a new feature in Accumulo 2.1.0 which allows compaction work to run outside of Tablet Servers.
Overview
There are two types of compactions in Accumulo - Minor and Major. Minor compactions flush recently written data from memory to a new file. Major compactions merge two or more Tablet files together into one new file. Starting in 2.1 Tablet Servers can run multiple major compactions for a Tablet concurrently; there is no longer a single thread pool per Tablet Server that runs compactions. Major compactions can be resource intensive and may run for a long time depending on several factors, to include the number and size of the input files, and the iterators configured to run during major compaction. Additionally, the Tablet Server does not currently have a mechanism in place to stop a major compaction that is taking too long or using too many resources. There is a mechanism to throttle the read and write speed of major compactions as a way to reduce the resource contention on a Tablet Server where many concurrent compactions are running. However, throttling compactions on a busy system will just lead to an increasing amount of queued compactions. Finally, major compaction work can be wasted in the event of an untimely death of the Tablet Server or if a Tablet is migrated to another Tablet Server.
An external compaction is a major compaction that occurs outside of a Tablet Server. The external compaction feature is an extension of the major compaction service in the Tablet Server and is configured as part of the systems compaction service configuration. Thus, it is an optional feature. The goal of the external compaction feature is to overcome some of the drawbacks of the Major compactions that happen inside the Tablet Server. Specifically, external compactions:
- Allow major compactions to continue when the originating TabletServer dies
- Allow major compactions to occur while a Tablet migrates to a new Tablet Server
- Reduce the load on the TabletServer, giving it more cycles to insert mutations and respond to scans (assuming it’s running on different hosts). MapReduce jobs and compactions can lower the effectiveness of processor and page caches for scans, so moving compactions off the host can be beneficial.
- Allow major compactions to be scaled differently than the number of TabletServers, giving users more flexibility in allocating resources.
- Even out hotspots where a few Tablet Servers have a lot of compaction work. External compactions allow this work to spread much wider than previously possible.
The external compaction feature in Apache Accumulo version 2.1.0 adds two new system-level processes and new configuration properties. The new system-level processes are the Compactor and the Compaction Coordinator.
- The Compactor is a process that is responsible for executing a major compaction. There can be many Compactor’s running on a system. The Compactor communicates with the Compaction Coordinator to get information about the next major compaction it will run and to report the completion state.
- The Compaction Coordinator is a single process like the Manager. It is responsible for communicating with the Tablet Servers to gather information about queued external compactions, to reserve a major compaction on the Compactor’s behalf, and to report the completion status of the reserved major compaction. For external compactions that complete when the Tablet is offline, the Compaction Coordinator buffers this information and reports it later.
Details
Before we explain the implementation for external compactions, it’s probably
useful to explain the changes for major compactions that were made in the 2.1.0
branch before external compactions were added. This is most apparent in the
tserver.compaction.major.service and table.compaction.dispatcher configuration
properties. The simplest way to explain this is that you can now define a
service for executing compactions and then assign that service to a table
(which implies you can have multiple services assigned to different tables).
This gives the flexibility to prevent one table’s compactions from impacting
another table. Each service has named thread pools with size thresholds.
Configuration
The configuration below defines a compaction service named cs1 using the DefaultCompactionPlanner that is configured to have three named thread pools (small, medium, and large). Each thread pool is configured with a number of threads to run compactions and a size threshold. If the sum of the input file sizes is less than 16MB, then the major compaction will be assigned to the small pool, for example.
tserver.compaction.major.service.cs1.planner=org.apache.accumulo.core.spi.compaction.DefaultCompactionPlanner
tserver.compaction.major.service.cs1.planner.opts.executors=[
{"name":"small","type":"internal","maxSize":"16M","numThreads":8},
{"name":"medium","type":"internal","maxSize":"128M","numThreads":4},
{"name":"large","type":"internal","numThreads":2}]
To assign compaction service cs1 to the table ci, you would use the following properties:
config -t ci -s table.compaction.dispatcher=org.apache.accumulo.core.spi.compaction.SimpleCompactionDispatcher
config -t ci -s table.compaction.dispatcher.opts.service=cs1
A small modification to the tserver.compaction.major.service.cs1.planner.opts.executors property in the example above would enable it to use external compactions. For example, let’s say that we wanted all of the large compactions to be done externally, you would use this configuration:
tserver.compaction.major.service.cs1.planner.opts.executors=[
{"name":"small","type":"internal","maxSize":"16M","numThreads":8},
{"name":"medium","type":"internal","maxSize":"128M","numThreads":4},
{"name":"large","type":"external","queue":"DCQ1"}]'
In this example the queue DCQ1 can be any arbitrary name and allows you to define multiple pools of Compactor’s.
Behind these new configurations in 2.1 lies a new algorithm for choosing which files to compact. This algorithm attempts to find the smallest set of files that meets the compaction ratio criteria. Prior to 2.1, Accumulo looked for the largest set of files that met the criteria. Both algorithms do logarithmic amounts of work. The new algorithm better utilizes multiple thread pools available for running comactions of different sizes.
Compactor
A Compactor is started with the name of the queue for which it will complete major compactions. You pass in the queue name when starting the Compactor, like so:
bin/accumulo compactor -q DCQ1
Once started the Compactor tries to find the location of the Compaction Coordinator in ZooKeeper and connect to it. Then, it asks the Compaction Coordinator for the next compaction job for the queue. The Compaction Coordinator will return to the Compactor the necessary information to run the major compaction, assuming there is work to be done. Note that the class performing the major compaction in the Compactor is the same one used in the Tablet Server, so we are just transferring all of the input parameters from the Tablet Server to the Compactor. The Compactor communicates information back to the Compaction Coordinator when the compaction has started, finished (successfully or not), and during the compaction (progress updates).
Compaction Coordinator
The Compaction Coordinator is a singleton process in the system like the Manager. Also, like the Manager it supports standby Compaction Coordinator’s using locks in ZooKeeper. The Compaction Coordinator is started using the command:
bin/accumulo compaction-coordinator
When running, the Compaction Coordinator polls the TabletServers for summary information about their external compaction queues. It keeps track of the major compaction priorities for each Tablet Server and queue. When a Compactor requests the next major compaction job the Compaction Coordinator finds the Tablet Server with the highest priority major compaction for that queue and communicates with that Tablet Server to reserve an external compaction. The priority in this case is an integer value based on the number of input files for the compaction. For system compactions, the number is negative starting at -32768 and increasing to -1 and for user compactions it’s a non-negative number starting at 0 and limited to 32767. When the Tablet Server reserves the external compaction an entry is written into the metadata table row for the Tablet with the address of the Compactor running the compaction and all of the configuration information passed back from the Tablet Server. Below is an example of the ecomp metadata column:
2;10ba2e8ba2e8ba5 ecomp:ECID:94db8374-8275-4f89-ba8b-4c6b3908bc50 [] {"inputs":["hdfs://accucluster/accumulo/tables/2/t-00000ur/A00001y9.rf","hdfs://accucluster/accumulo/tables/2/t-00000ur/C00005lp.rf","hdfs://accucluster/accumulo/tables/2/t-00000ur/F0000dqm.rf","hdfs://accucluster/accumulo/tables/2/t-00000ur/F0000dq1.rf"],"nextFiles":[],"tmp":"hdfs://accucluster/accumulo/tables/2/t-00000ur/C0000dqs.rf_tmp","compactor":"10.2.0.139:9133","kind":"SYSTEM","executorId":"DCQ1","priority":-32754,"propDels":true,"selectedAll":false}
When the Compactor notifies the Compaction Coordinator that it has finished the major compaction, the Compaction Coordinator attempts to notify the Tablet Server and inserts an external compaction final state marker into the metadata table. Below is an example of the final state marker:
~ecompECID:de6afc1d-64ae-4abf-8bce-02ec0a79aa6c : [] {"extent":{"tableId":"2"},"state":"FINISHED","fileSize":12354,"entries":100000}
If the Compaction Coordinator is able to reach the Tablet Server and that Tablet Server is still hosting the Tablet, then the compaction is committed and both of the entries are removed from the metadata table. In the case that the Tablet is offline when the compaction attempts to commit, there is a thread in the Compaction Coordinator that looks for completed, but not yet committed, external compactions and periodically attempts to contact the Tablet Server hosting the Tablet to commit the compaction. The Compaction Coordinator periodically removes the final state markers related to Tablets that no longer exist. In the case of an external compaction failure the Compaction Coordinator notifies the Tablet and the Tablet cleans up file reservations and removes the metadata entry.
Edge Cases
There are several situations involving external compactions that we tested as part of this feature. These are:
- Tablet migration
- When a user initiated compaction is canceled
- What a Table is taken offline
- When a Tablet is split or merged
- Coordinator restart
- Tablet Server death
- Table deletion
Compactors periodically check if the compaction they are running is related to a deleted table, split/merged Tablet, or canceled user initiated compaction. If any of these cases happen the Compactor interrupts the compaction and notifies the Compaction Coordinator. An external compaction continues in the case of Tablet Server death, Tablet migration, Coordinator restart, and the Table being taken offline.
Cluster Test
The following tests were run on a cluster to exercise this new feature.
- Run continuous ingest for 24h with large compactions running externally in an autoscaled Kubernetes cluster.
- After ingest completion, started a full table compaction with all compactions running externally.
- Run continuous ingest verification process that looks for lost data.
Setup
For these tests Accumulo, Zookeeper, and HDFS were run on a cluster in Azure setup by Muchos and external compactions were run in a separate Kubernetes cluster running in Azure. The Accumulo cluster had the following configuration.
- Centos 7
- Open JDK 11
- Zookeeper 3.6.2
- Hadoop 3.3.0
- Accumulo 2.1.0-SNAPSHOT dad7e01
- 23 D16s_v4 VMs, each with 16x128G HDDs stripped using LVM. 22 were workers.
The following diagram shows how the two clusters were setup. The Muchos and Kubernetes clusters were on the same private vnet, each with its own /16 subnet in the 10.x.x.x IP address space. The Kubernetes cluster that ran external compactions was backed by at least 3 D8s_v4 VMs, with VMs autoscaling with the number of pods running.
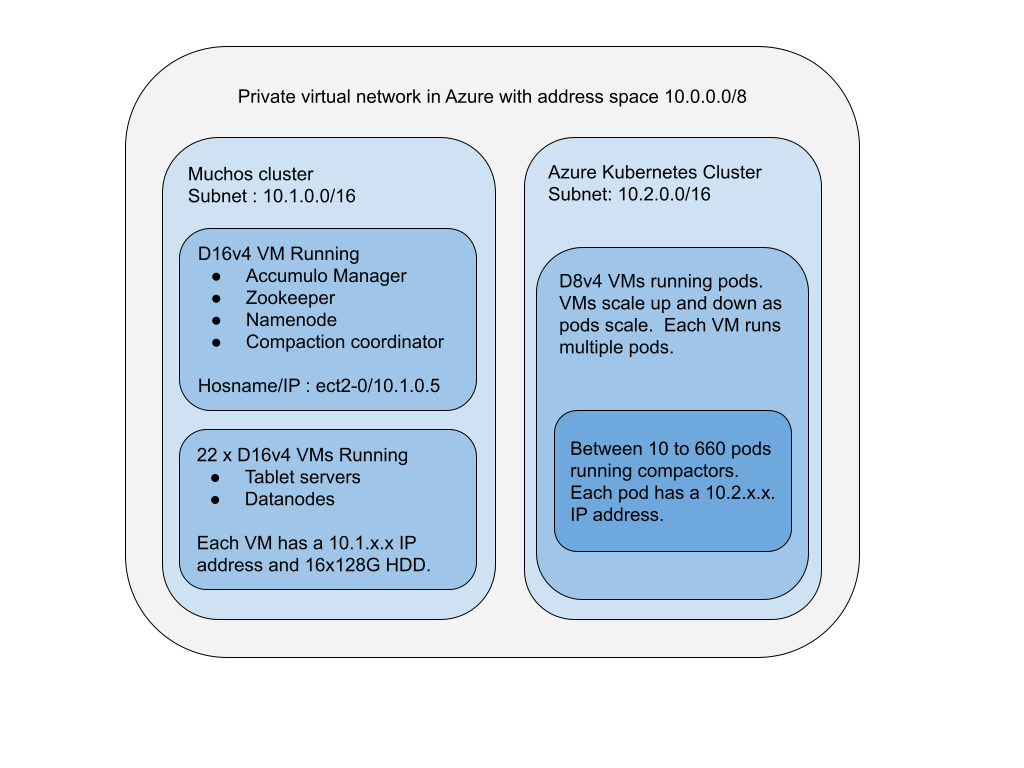
One problem we ran into was communication between Compactors running inside Kubernetes with processes like the Compaction Coordinator and DataNodes running outside of Kubernetes in the Muchos cluster. For some insights into how these problems were overcome, checkout the comments in the deployment spec used.
Configuration
The following Accumulo shell commands set up a new compaction service named cs1. This compaction service has an internal executor with 4 threads named small for compactions less than 32M, an internal executor with 2 threads named medium for compactions less than 128M, and an external compaction queue named DCQ1 for all other compactions.
config -s 'tserver.compaction.major.service.cs1.planner.opts.executors=[{"name":"small","type":"internal","maxSize":"32M","numThreads":4},{"name":"medium","type":"internal","maxSize":"128M","numThreads":2},{"name":"large","type":"external","queue":"DCQ1"}]'
config -s tserver.compaction.major.service.cs1.planner=org.apache.accumulo.core.spi.compaction.DefaultCompactionPlanner
The continuous ingest table was configured to use the above compaction service. The table’s compaction ratio was also lowered from the default of 3 to 2. A lower compaction ratio results in less files per Tablet and more compaction work.
config -t ci -s table.compaction.dispatcher=org.apache.accumulo.core.spi.compaction.SimpleCompactionDispatcher
config -t ci -s table.compaction.dispatcher.opts.service=cs1
config -t ci -s table.compaction.major.ratio=2
The Compaction Coordinator was manually started on the Muchos VM where the Accumulo Manager, Zookeeper server, and the Namenode were running. The following command was used to do this.
nohup accumulo compaction-coordinator >/var/data/logs/accumulo/compaction-coordinator.out 2>/var/data/logs/accumulo/compaction-coordinator.err &
To start Compactors, Accumulo’s
docker image was
built from the next-release branch by checking out the Apache Accumulo git
repo at commit dad7e01 and building the binary distribution using the
command mvn clean package -DskipTests. The resulting tar file was copied to
the accumulo-docker base directory and the image was built using the command:
docker build --build-arg ACCUMULO_VERSION=2.1.0-SNAPSHOT --build-arg ACCUMULO_FILE=accumulo-2.1.0-SNAPSHOT-bin.tar.gz \
--build-arg HADOOP_FILE=hadoop-3.3.0.tar.gz \
--build-arg ZOOKEEPER_VERSION=3.6.2 --build-arg ZOOKEEPER_FILE=apache-zookeeper-3.6.2-bin.tar.gz \
-t accumulo .
The Docker image was tagged and then pushed to a container registry accessible by Kubernetes. Then the following commands were run to start the Compactors using accumulo-compactor-muchos.yaml. The yaml file contains comments explaining issues related to IP addresses and DNS names.
kubectl apply -f accumulo-compactor-muchos.yaml
kubectl autoscale deployment accumulo-compactor --cpu-percent=80 --min=10 --max=660
The autoscale command causes Compactors to scale between 10 and 660 pods based on CPU usage. When pods average CPU is above 80%, then pods are added to meet the 80% goal. When it’s below 80%, pods are stopped to meet the 80% goal with 5 minutes between scale down events. This can sometimes lead to running compactions being stopped. During the test there were ~537 dead compactions that were probably caused by this (there were 44K successful external compactions). The max of 660 was chosen based on the number of datanodes in the Muchos cluster. There were 22 datanodes and 30x22=660, so this conceptually sets a limit of 30 external compactions per datanode. This was well tolerated by the Muchos cluster. One important lesson we learned is that external compactions can strain the HDFS DataNodes, so it’s important to consider how many concurrent external compactions will be running. The Muchos cluster had 22x16=352 cores on the worker VMs, so the max of 660 exceeds what the Muchos cluster could run itself.
Ingesting data
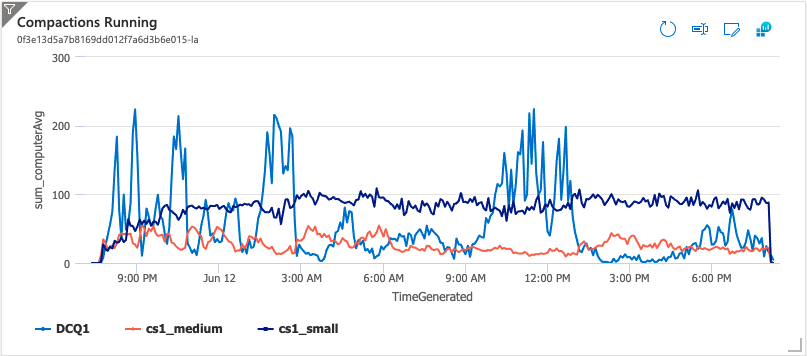
After starting Compactors, 22 continuous ingest clients (from accumulo-testing) were started. The following plot shows the number of compactions running in the three different compaction queues configured. The executor cs1_small is for compactions <= 32M and it stayed pretty busy as minor compactions constantly produce new small files. In 2.1.0 merging minor compactions were removed, so it’s important to ensure a compaction queue is properly configured for new small files. The executor cs1_medium was for compactions >32M and <=128M and it was not as busy, but did have steady work. The external compaction queue DCQ1 processed all compactions over 128M and had some spikes of work. These spikes are to be expected with continuous ingest as all Tablets are written to evenly and eventually all of the Tablets need to run large compactions around the same time.
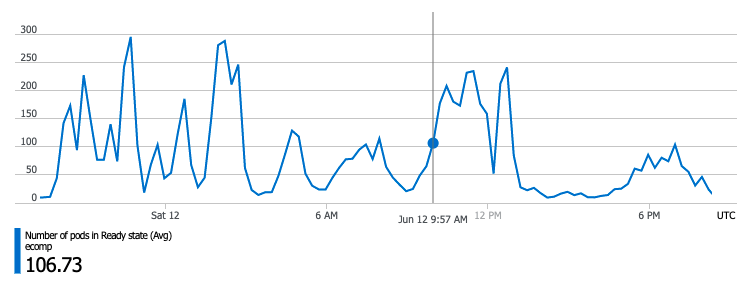
The following plot shows the number of pods running in Kubernetes. As Compactors used more and less CPU the number of pods automatically scaled up and down.
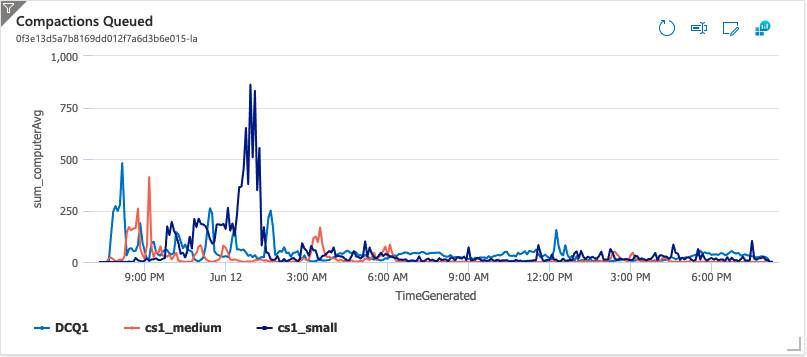
The following plot shows the number of compactions queued. When the compactions queued for cs1_small spiked above 750, it was adjusted from 4 threads per Tablet Server to 6 threads. This configuration change was made while everything was running and the Tablet Servers saw it and reconfigured their thread pools on the fly.
The metrics emitted by Accumulo for these plots had the following names.
- TabletServer1.tserver.compactionExecutors.e_DCQ1_queued
- TabletServer1.tserver.compactionExecutors.e_DCQ1_running
- TabletServer1.tserver.compactionExecutors.i_cs1_medium_queued
- TabletServer1.tserver.compactionExecutors.i_cs1_medium_running
- TabletServer1.tserver.compactionExecutors.i_cs1_small_queued
- TabletServer1.tserver.compactionExecutors.i_cs1_small_running
Tablet servers emit metrics about queued and running compactions for every compaction executor configured. User can observe these metrics and tune the configuration based on what they see, as was done in this test.
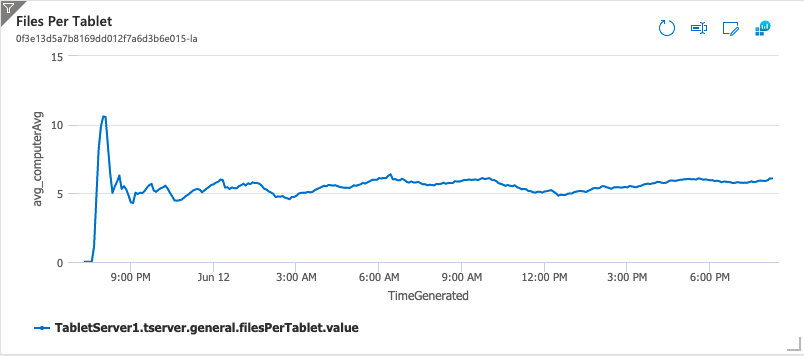
The following plot shows the average files per Tablet during the test. The numbers are what would be expected for a compaction ratio of 2 when the system is keeping up with compaction work. Also, animated GIFs were created to show a few tablets files over time.
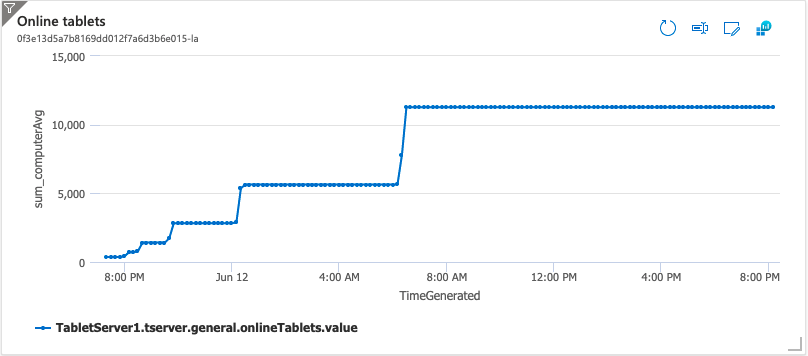
The following is a plot of the number Tablets during the test. Eventually there were 11.28K Tablets around 512 Tablets per Tablet Server. The Tablets were close to splitting again at the end of the test as each Tablet was getting close to 1G.
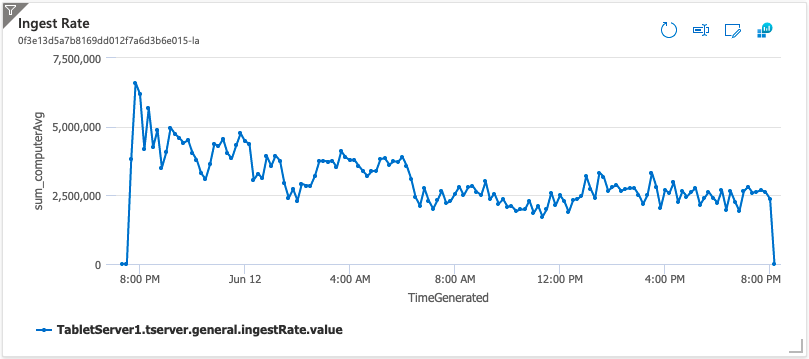
The following plot shows ingest rate over time. The rate goes down as the number of Tablets per Tablet Server goes up, this is expected.
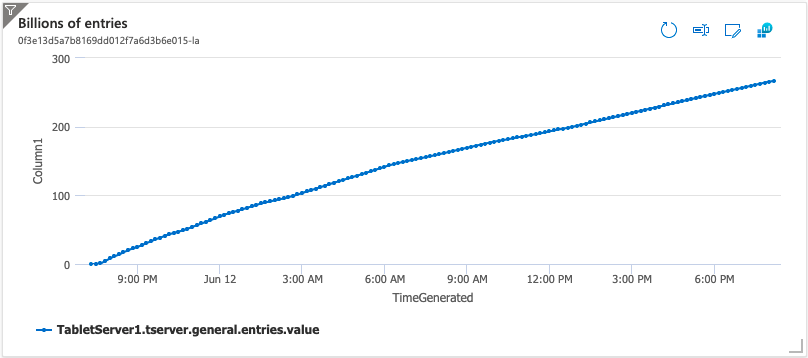
The following plot shows the number of key/values in Accumulo during the test. When ingest was stopped, there were 266 billion key values in the continuous ingest table.
Full table compaction
After stopping ingest and letting things settle, a full table compaction was kicked off. Since all of these compactions would be over 128M, all of them were scheduled on the external queue DCQ1. The two plots below show compactions running and queued for the ~2 hours it took to do the compaction. When the compaction was initiated there were 10 Compactors running in pods. All 11K Tablets were queued for compaction and because the pods were always running high CPU Kubernetes kept adding pods until the max was reached resulting in 660 Compactors running until all the work was done.
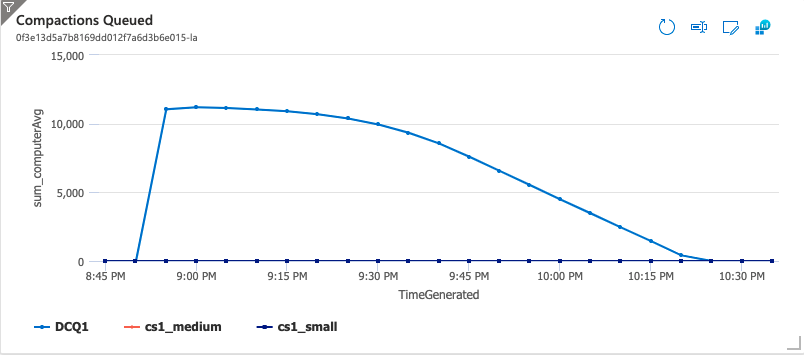
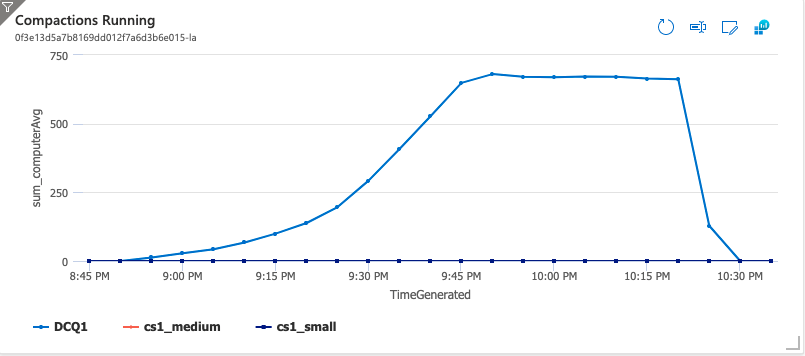
Verification
After running everything mentioned above, the continuous ingest verification map reduce job was run. This job looks for holes in the linked list produced by continuous ingest which indicate Accumulo lost data. No holes were found. The counts below were emitted by the job. If there were holes a non-zero UNDEFINED count would be present.
org.apache.accumulo.testing.continuous.ContinuousVerify$Counts
REFERENCED=266225036149
UNREFERENCED=22010637
Hurdles
How to Scale Up
We ran into several issues running the Compactors in Kubernetes. First, we knew that we could use Kubernetes Horizontal Pod Autoscaler (HPA) to scale the Compactors up and down based on load. But the question remained how to do that. Probably the best metric to use for scaling the Compactors is the size of the external compaction queue. Another possible solution is to take the DataNode utilization into account somehow. We found that in scaling up the Compactors based on their CPU usage we could overload DataNodes. Once DataNodes were overwhelmed, Compactors CPU would drop and the number of pods would naturally scale down.
To use custom metrics you would need to get the metrics from Accumulo into a metrics store that has a metrics adapter. One possible solution, available in Hadoop 3.3.0, is to use Prometheus, the Prometheus Adapter, and enable the Hadoop PrometheusMetricsSink added in HADOOP-16398 to expose the custom queue size metrics. This seemed like the right solution, but it also seemed like a lot of work that was outside the scope of this blog post. Ultimately we decided to take the simplest approach - use the native Kubernetes metrics-server and scale off CPU usage of the Compactors. As you can see in the “Compactions Queued” and “Compactions Running” graphs above from the full table compaction, it took about 45 minutes for Kubernetes to scale up Compactors to the maximum configured (660). Compactors likely would have been scaled up much faster if scaling was done off the queued compactions instead of CPU usage.
Gracefully Scaling Down
The Kubernetes Pod termination process provides a mechanism for the user to define a pre-stop hook that will be called before the Pod is terminated. Without this hook Kubernetes sends a SIGTERM to the Pod, followed by a user-defined grace period, then a SIGKILL. For the purposes of this test we did not define a pre-stop hook or a grace period. It’s likely possible to handle this situation more gracefully, but for this test our Compactors were killed and the compaction work lost when the HPA decided to scale down the Compactors. It was a good test of how we handled failed Compactors. Investigation is needed to determine if changes are needed in Accumulo to facilitate graceful scale down.
How to Connect
The other major issue we ran into was connectivity between the Compactors and
the other server processes. The Compactor communicates with ZooKeeper and the
Compaction Coordinator, both of which were running outside of Kubernetes. There
is no common DNS between the Muchos and Kubernetes cluster, but IPs were
visible to both. The Compactor connects to ZooKeeper to find the address of the
Compaction Coordinator so that it can connect to it and look for work. By
default the Accumulo server processes use the hostname as their address which
would not work as those names would not resolve inside the Kubernetes cluster.
We had to start the Accumulo processes using the -a argument and set the
hostname to the IP address. Solving connectivity issues between components
running in Kubernetes and components external to Kubernetes depends on the capabilities
available in the environment and the -a option may be part of the solution.
Conclusion
In this blog post we introduced the concept and benefits of external compactions, the new server processes and how to configure the compaction service. We deployed a 23-node Accumulo cluster using Muchos with a variable sized Kubernetes cluster that dynamically scaled Compactors on 3 to 100 compute nodes from 10 to 660 instances. We ran continuous ingest on the Accumulo cluster to create compactions that were run both internal and external to the Tablet Server and demonstrated external compactions completing successfully and Compactors being killed.
We discussed also running the following test, but did not have time.
- Agitating the Compaction Coordinator, Tablet Servers and Compactors while ingest was running.
- Comparing the impact on queries for internal vs external compactions.
- Having multiple external compaction queues, each with its own set of autoscaled Compactor pods.
- Forcing full table compactions while ingest was running.
The test we ran shows that basic functionality works well, it would be nice to stress the feature in other ways though.
View all posts in the news archive