Using HDFS Erasure Coding with Accumulo
Author: Ed Seidl
Date: 17 Sep 2019
HDFS normally stores multiple copies of each file for both performance and durability reasons. The number of copies is controlled via HDFS replication settings, and by default is set to 3. Hadoop 3, introduced the use of erasure coding (EC), which improves durability while decreasing overhead. Since Accumulo 2.0 now supports Hadoop 3, it’s time to take a look at whether using EC with Accumulo makes sense.
EC Intro
By default HDFS achieves durability via block replication. Usually the replication count is 3, resulting in a storage overhead of 200%. Hadoop 3 introduced EC as a better way to achieve durability. More info can be found here. EC behaves much like RAID 5 or 6…for k blocks of data, m blocks of parity data are generated, from which the original data can be recovered in the event of disk or node failures (erasures, in EC parlance). A typical EC scheme is Reed-Solomon 6-3, where 6 data blocks produce 3 parity blocks, an overhead of only 50%. In addition to doubling the available disk space, RS-6-3 is also more fault tolerant…a loss of 3 data blocks can be tolerated, where triple replication can only lose two blocks.
More storage, better resiliency, so what’s the catch? One concern is the time spent calculating the parity blocks. Unlike replication , where a client writes a block, and then the DataNodes replicate the data, an EC HDFS client is responsible for computing the parity and sending that to the DataNodes. This increases the CPU and network load on the client. The CPU hit can be mitigated by using Intels ISA-L library, but only on CPUs that support AVX or AVX2 instructions. (See EC Myths and EC Introduction for some interesting claims). In addition, unlike the serial replication I/O path, the EC I/O path is parallel providing greater throughput. In our testing, sequential writes to an EC directory were as much as 3 times faster than a replication directory , and reads were up to 2 times faster.
Another side effect of EC is loss of data locality. For performance reasons, EC data blocks are striped, so multiple DataNodes must be contacted to read a single block of data. For large sequential reads this is not a problem, but it can be an issue for small random lookups. For the latter case, using RS 6-3 with 64KB stripes mitigates some of the random lookup pain without compromising sequential read/write performance.
Important Warning
Before continuing, an important caveat; the current implementation of EC on Hadoop supports neither hsync nor hflush. Both of these operations are silent no-ops (EC limitations). We discovered this the hard way when a data center power loss resulted in write-ahead log corruption, which were stored in an EC directory. To avoid this problem ensure all WAL directories use replication. It’s probably a good idea to keep the accumulo namespace replicated as well, but we have no evidence to back up that assertion. As with all things, don’t test on production data.
EC Performance
To test EC performance, we created a series of clusters on AWS. Our Accumulo stack consisted of Hadoop 3.1.1 built with the Intel ISA-L library enabled, Zookeeper 3.4.13, and Accumulo 1.9.3 configured to work with Hadoop 3 (we did our testing before the official release of Accumulo 2.0). The encoding policy is set per-directory using the hdfs command-line tool. To set the encoding policy for an Accumulo table, first find the table ID (for instance using the Accumulo shell’s “table -l” command), and then from the command line set the policy for the corresponding directory under /accumulo/tables. Note that changing the policy on a directory will set the policy for child directories, but will not change any files contained within. To change the policy on an existing Accumulo table, you must first set the encoding policy, and then run a major compaction to rewrite the RFiles for the table.
Our first tests were of sequential read and write performance straight to HDFS. For this test we had a cluster of 32 HDFS nodes (c5.4xlarge AWS instances), 16 Spark nodes (r5.4xlarge), 3 zookeepers (r5.xlarge), and 1 master (r5.2xlarge).
The first table below shows the results for writing a 1TB file. The results are the average of three runs for each of the directory encodings Reed-Solomon (RS) 6-3 with 64KB stripes, RS 6-3 with 1MB stripes, RS 10-4 with 1MB stripes, and the default triple replication. We also varied the number of concurrent Spark executors, performing tests with 16 executors that did not stress the cluster in any area, and with 128 executors which exhausted our network bandwidth allotment of 5 Gbps. As can be seen, in the 16 executor environment, we saw greater than a 3X bump in throughput using RS 10-4 with 1MB stripes over triple replication. At saturation, the speed up was still over 2X, which is in line with the results from EC Myths. Also of note, using RS 6-3 with 64KB stripes performed better than the same with 1MB stripes, which is a nice result for Accumulo, as we’ll show later.
| Encoding | 16 executors | 128 executors |
|---|---|---|
| Replication | 2.19 GB/s | 4.13 GB/s |
| RS 6-3 64KB | 6.33 GB/s | 8.11 GB/s |
| RS 6-3 1MB | 6.22 GB/s | 7.93 GB/s |
| RS 10-4 1MB | 7.09 GB/s | 8.34 GB/s |
Our read tests are not as dramatic as those in EC Myths, but still looking good for EC. Here we show the results for reading back the 1TB file created in the write test using 16 Spark executors. In addition to the straight read tests, we also performed tests with 2 DataNodes disabled to simulate the performance hit of failures which require data repair in the foreground. Finally, we tested the read performance after a background rebuild of the filesystem. We did this to see if the foreground rebuild or the loss of 2 DataNodes was the major contributor to any performance degradation. As can be seen, EC read performance is close to 2X faster than replication, even in the face of failures.
| Encoding | 32 nodes no failures |
30 nodes with failures |
30 nodes no failures |
|---|---|---|---|
| Replication | 3.95 GB/s | 3.99 GB/s | 3.89 GB/s |
| RS 6-3 64KB | 7.36 GB/s | 7.27 GB/s | 7.16 GB/s |
| RS 6-3 1MB | 6.59 GB/s | 6.47 GB/s | 6.53 GB/s |
| RS 10-4 1MB | 6.21 GB/s | 6.08 GB/s | 6.21 GB/s |
Accumulo Performance with EC
While the above results are impressive, they are not representative of how Accumulo uses HDFS. For starters, Accumulo sequential I/O is doing far more than just reading or writing files; compression and serialization, for example, place quite a load upon the tablet server CPUs. An example to illustrate this is shown below. The time in minutes to bulk-write 400 million rows to RFiles with 40 Spark executors is listed for both EC using RS 6-3 with 1MB stripes and triple replication. The choice of compressor has a much more profound effect on the write times than the choice of underlying encoding for the directory being written to (although without compression EC is much faster than replication).
| Compressor | RS 6-3 1MB | Replication | File size (GB) |
|---|---|---|---|
| gz | 2.7 | 2.7 | 21.3 |
| none | 2.0 | 3.0 | 158.5 |
| snappy | 1.6 | 1.6 | 38.4 |
Of much more importance to Accumulo performance is read latency. A frequent use case for our group is to obtain a number of row IDs from an index and then use a BatchScanner to read those individual rows. In this use case, the time to access a single row is far more important than the raw I/O performance. To test Accumulo’s performance with EC for this use case, we did a series of tests against a 10 billion row table, with each row consisting of 10 columns. 16 Spark executors each performed 10000 queries, where each query sought 10 random rows. Thus 16 million individual rows were returned in batches of 10. For each batch of 10, the time in milliseconds was captured, and theses times were collected in a histogram of 50ms buckets, with a catch-all bucket for queries that took over 1 second. For this test we reconfigured our cluster to make use of c5n.4xlarge nodes featuring must faster networking speeds (15 Gbps sustained vs 5 Gbps for c5.4xlarge). Because these nodes are in short supply, we ran with only 16 HDFS nodes (c5n.4xlarge), but still had 16 Spark nodes (also c5n.4xlarge). Zookeeper and master nodes remained the same.
In the table below, we show the min, max, and average times in milliseconds for each batch of 10 across four different encoding policies. The clear winner here is replication, and the clear loser RS 10-4 with 1MB stripes, but RS 6-3 with 64KB stripes is not looking too bad.
| Encoding | Min | Avg | Max |
|---|---|---|---|
| RS 10-4 1MB | 40 | 105 | 2148 |
| RS 6-3 1MB | 30 | 68 | 1297 |
| RS 6-3 64KB | 23 | 43 | 1064 |
| Replication | 11 | 23 | 731 |
The above results also hold in the event of errors. The next table shows the same test, but with 2 DataNodes disabled to simulate failures that require foreground rebuilds. Again, replication wins, and RS 10-4 1MB loses, but RS 6-3 64KB remains a viable option.
| Encoding | Min | Avg | Max |
|---|---|---|---|
| RS 10-4 1MB | 53 | 143 | 3221 |
| RS 6-3 1MB | 34 | 113 | 1662 |
| RS 6-3 64KB | 24 | 61 | 1402 |
| Replication | 12 | 26 | 304 |
The images below show a plots of the histograms. The third plot was generated with 14 HDFS DataNodes, but after all missing data had been repaired. Again, this was done to see how much of the performance degradation could be attributed to missing data, and how much to simply having less computing power available.
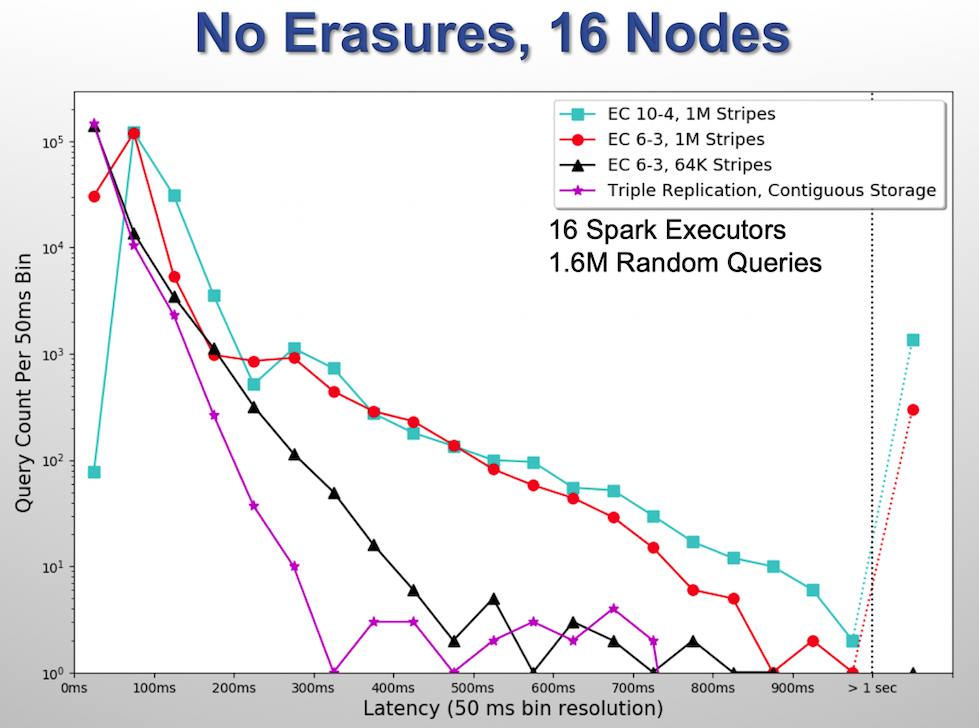
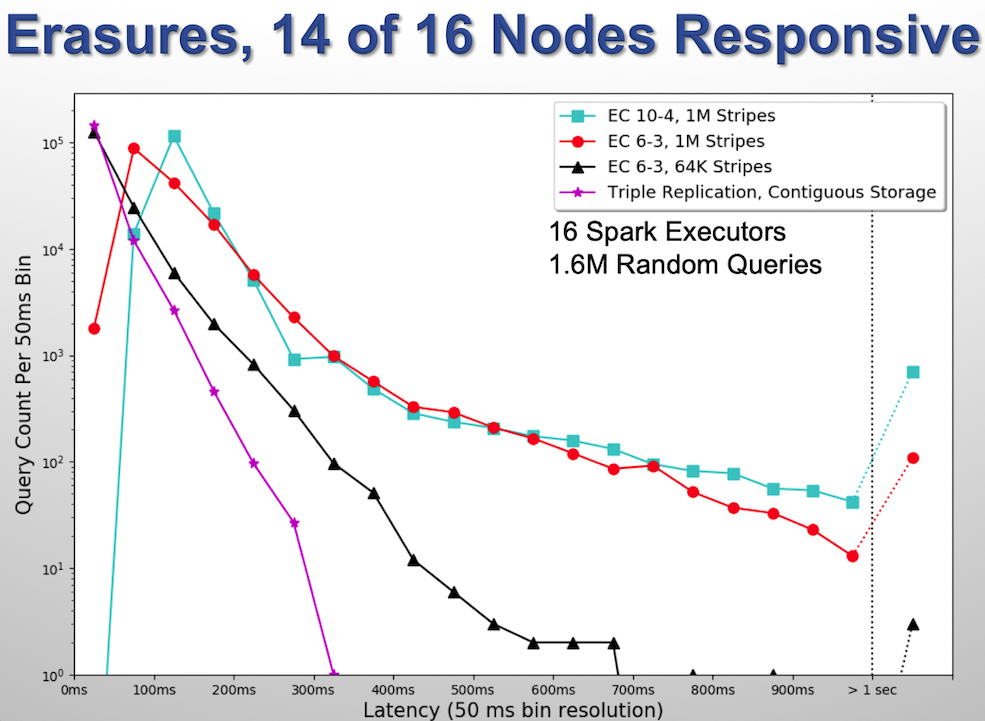
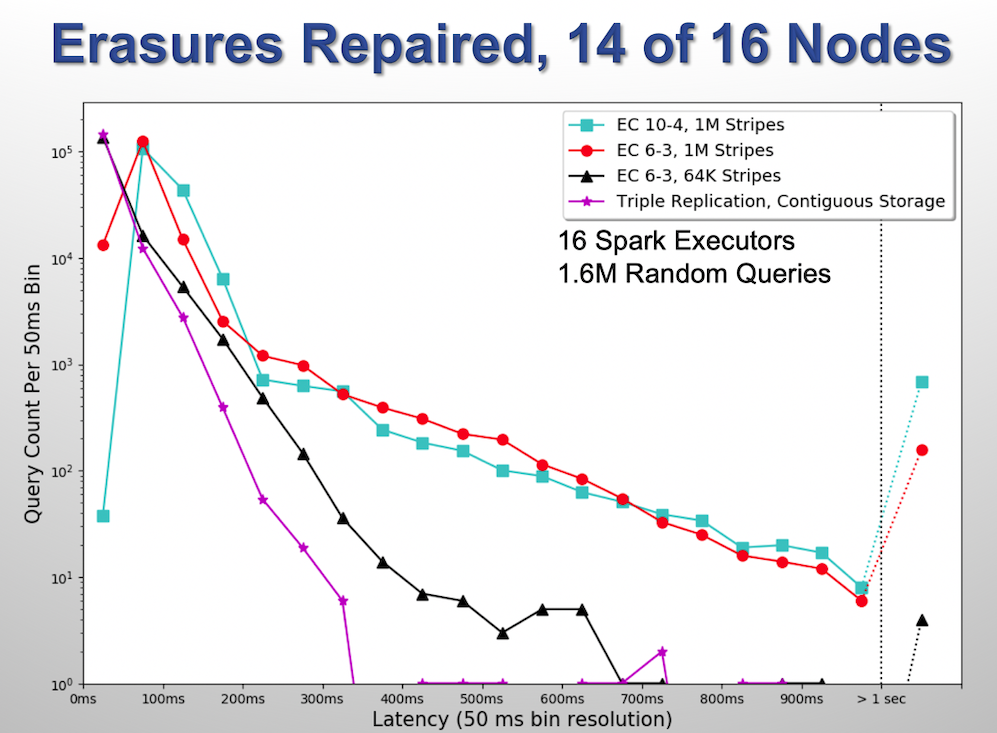
Conclusion
HDFS with erasure coding has the potential to double your available Accumulo storage, at the cost of a hit in random seek times, but a potential increase in sequential scan performance. We will be proposing some changes to Accumulo to make working with EC a bit easier. Our initial thoughts are collected in this Accumulo dev list post.
View all posts in the news archive