Top 10 Reasons to Upgrade
Author: Mike Miller
Date: 12 Aug 2019
Reviewer(s) Keith Turner
Accumulo 2.0 has been in development for quite some time now and is packed with new features, bug fixes, performance improvements and redesigned components. All of these changes bring challenges when upgrading your production cluster so you may be wondering… why should I upgrade?
My top 10 reasons to upgrade. For all changes see the release notes
- Summaries
- New Bulk Import
- Simplified Scripts and Config
- New Monitor
- New APIs
- Offline creation
- Search Documentation
- On disk encryption
- ZStandard Compression
- New Scan Executors
Summaries
This feature allows detailed stats about Tables to be written directly into Accumulo files (R-Files). Summaries can be used to make precise decisions about your data. Once configured, summaries become a part of your Tables, so they won’t impact ingest or query performance of your cluster.
Here are some example use cases:
- A compaction could automatically run if deletes compose more than 25% of the data
- An admin could optimize compactions by configuring specific age off of data
- An admin could analyze R-File summaries for better performance tuning of a cluster
For more info check out the summary docs for 2.0
New Bulk Import
Bulk Ingest was completely redone for 2.0. Previously, Bulk Ingest relied on expensive inspections of R-Files across multiple Tablet Servers. With enough data, an old Bulk Ingest operation could easily hold up simpler Table operations and critical compactions of files.
The new Bulk Ingest gives the user control over the R-File inspection, allows for offline bulk ingesting and provides performance improvements.
Simplified Scripts and Config
Many improvements were done to the scripts and configuration. See Mike’s description of the improvements.
New Monitor
The Monitor has been re-written using REST, Javascript and more modern Web Tech. It is faster, cleaner and more maintainable than the previous version. Here is a screen shot:
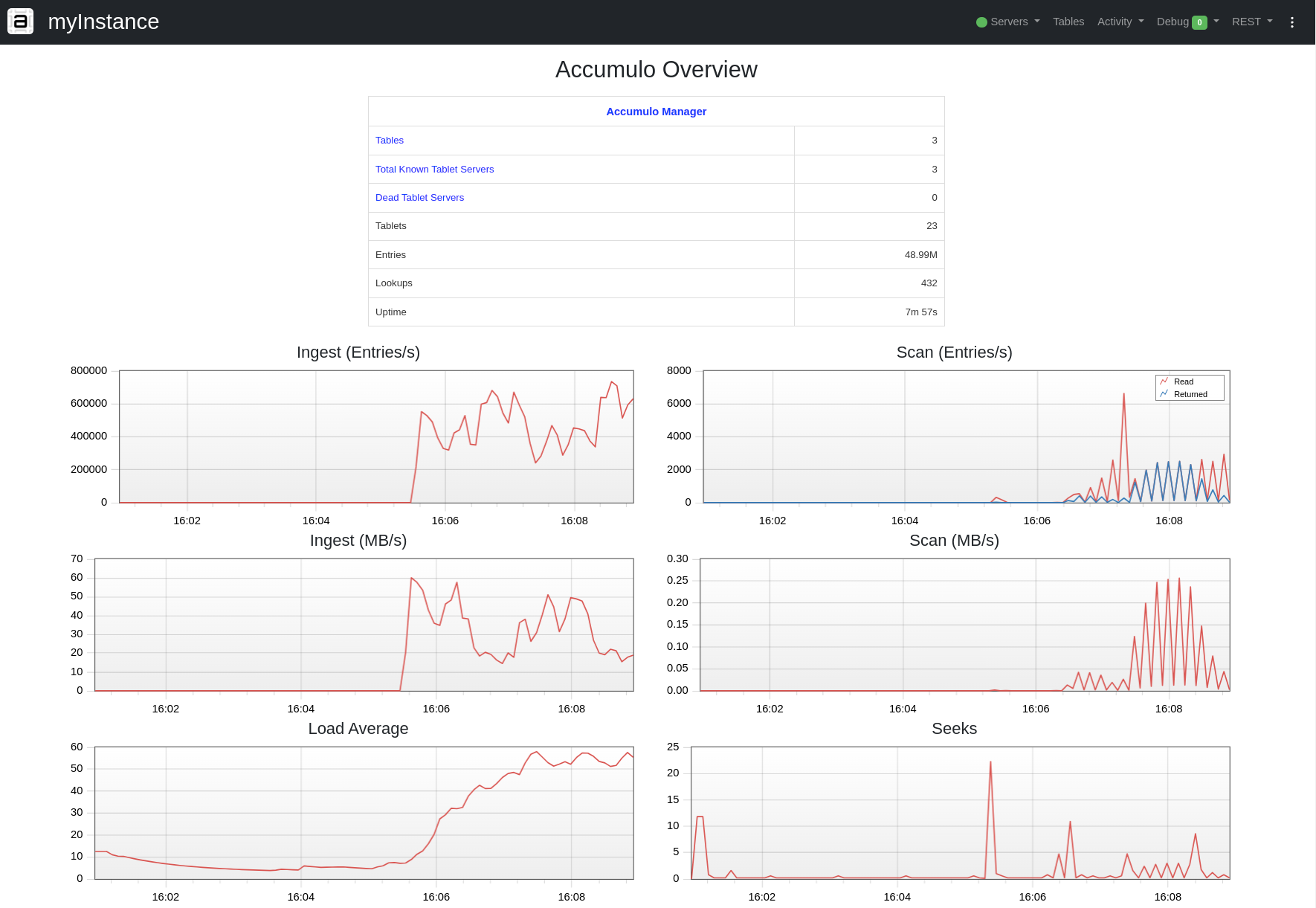
New APIs
Connecting to Accumulo is now easier with a single point of entry for clients. It can now be done with a fluent API, 2 imports and using minimal code:
import org.apache.accumulo.core.client.Accumulo;
import org.apache.accumulo.core.client.AccumuloClient;
try (AccumuloClient client = Accumulo.newClient()
.to("instance", "zk")
.as("user", "pass").build()) {
// use the client
client.tableOperations().create("newTable");
}
As you can see the client is also closable, which gives developers more control over resources. See the Accumulo entry point javadoc.
Key and Mutation have new fluent APIs, which now allow mixing of String and byte[] types.
Key newKey = Key.builder().row("foo").family("bar").build();
Mutation m = new Mutation("row0017");
m.at().family("001").qualifier(new byte[] {0,1}).put("v99");
m.at().family("002").qualifier(new byte[] {0,1}).delete();
More examples for Key and Mutation.
Table creation options
Tables can now be created with splits, which is much faster than creating a table and then adding splits. Tables can also be created in an offline state now. The new bulk import API supports offline tables. This enables the following method of getting a lot of data into a new table very quickly.
- Create offline table with splits
- Bulk import into new offline table
- Bring table online
See the javadoc for NewTableConfiguration and search for methods introduced in 2.0.0 for more information.
Search Documentation
New ability to quickly search documentation on the website. The user manual was completely redone for 2.0. Check it out here. Users can now quickly search the website across all 2.x documentation.
New Crypto
On disk encryption was redone to be more secure and flexible. For an in depth description of how Accumulo does on disk encryption, see the user manual. NOTE: This is currently an experimental feature. An experimental feature is considered a work in progress or incomplete and could change.
Zstandard compression
Support for Zstandard compression was added in 2.0. It has been measured to perform better than gzip (better compression ratio and speed) and snappy (better compression ratio). Checkout Facebook’s github for Zstandard and the table.file.compress.type property for configuring Accumulo.
New Scan Executors
Users now have more control over scans with the new scan executors. Tables can be configured to utilize these powerful new mechanisms using just a few properties, giving user control over things like scan prioritization and better cluster resource utilization.
For example, a cluster has a bunch of long running scans and one really fast scan. The long running scans will eat up a majority of the server resources causing the one really fast scan to be delayed. Scan executors allow an admin to configure the cluster in a way that allows the one fast scan to be prioritized and not have to wait.
Checkout some examples in the user guide.
View all posts in the news archive