User Manual: Table Configuration
** Next:** Table Design ** Up:** Apache Accumulo User Manual Version 1.4 ** Previous:** Development Clients ** Contents**
- Locality Groups
- Constraints
- Bloom Filters
- Iterators
- Block Cache
- Compaction
- Pre-splitting tables
- Merging tablets
- Delete Range
- Cloning Tables
Table Configuration
Accumulo tables have a few options that can be configured to alter the default behavior of Accumulo as well as improve performance based on the data stored. These include locality groups, constraints, bloom filters, iterators, and block cache.
Locality Groups
Accumulo supports storing of sets of column families separately on disk to allow clients to scan over columns that are frequently used together efficient and to avoid scanning over column families that are not requested. After a locality group is set Scanner and BatchScanner operations will automatically take advantage of them whenever the fetchColumnFamilies() method is used.
By default tables place all column families into the same ``default” locality group. Additional locality groups can be configured anytime via the shell or programmatically as follows:
Managing Locality Groups via the Shell
usage: setgroups <group>=<col fam>{,<col fam>}{ <group>=<col fam>{,<col
fam>}} [-?] -t <table>
user@myinstance mytable> setgroups -t mytable group_one=colf1,colf2
user@myinstance mytable> getgroups -t mytable
group_one=colf1,colf2
Managing Locality Groups via the Client API
Connector conn;
HashMap<String,Set<Text>> localityGroups =
new HashMap<String, Set<Text>>();
HashSet<Text> metadataColumns = new HashSet<Text>();
metadataColumns.add(new Text("domain"));
metadataColumns.add(new Text("link"));
HashSet<Text> contentColumns = new HashSet<Text>();
contentColumns.add(new Text("body"));
contentColumns.add(new Text("images"));
localityGroups.put("metadata", metadataColumns);
localityGroups.put("content", contentColumns);
conn.tableOperations().setLocalityGroups("mytable", localityGroups);
// existing locality groups can be obtained as follows
Map<String, Set<Text>> groups =
conn.tableOperations().getLocalityGroups("mytable");
The assignment of Column Families to Locality Groups can be changed anytime. The physical movement of column families into their new locality groups takes place via the periodic Major Compaction process that takes place continuously in the background. Major Compaction can also be scheduled to take place immediately through the shell:
user@myinstance mytable> compact -t mytable
Constraints
Accumulo supports constraints applied on mutations at insert time. This can be used to disallow certain inserts according to a user defined policy. Any mutation that fails to meet the requirements of the constraint is rejected and sent back to the client.
Constraints can be enabled by setting a table property as follows:
user@myinstance mytable> config -t mytable -s table.constraint.1=com.test.ExampleConstraint
user@myinstance mytable> config -t mytable -s table.constraint.2=com.test.AnotherConstraint
user@myinstance mytable> config -t mytable -f constraint
---------+--------------------------------+----------------------------
SCOPE | NAME | VALUE
---------+--------------------------------+----------------------------
table | table.constraint.1............ | com.test.ExampleConstraint
table | table.constraint.2............ | com.test.AnotherConstraint
---------+--------------------------------+----------------------------
Currently there are no general-purpose constraints provided with the Accumulo distribution. New constraints can be created by writing a Java class that implements the org.apache.accumulo.core.constraints.Constraint interface.
To deploy a new constraint, create a jar file containing the class implementing the new constraint and place it in the lib directory of the Accumulo installation. New constraint jars can be added to Accumulo and enabled without restarting but any change to an existing constraint class requires Accumulo to be restarted.
An example of constraints can be found in
accumulo/docs/examples/README.constraints with corresponding code under
accumulo/src/examples/simple/main/java/accumulo/examples/simple/constraints .
Bloom Filters
As mutations are applied to an Accumulo table, several files are created per tablet. If bloom filters are enabled, Accumulo will create and load a small data structure into memory to determine whether a file contains a given key before opening the file. This can speed up lookups considerably.
To enable bloom filters, enter the following command in the Shell:
user@myinstance> config -t mytable -s table.bloom.enabled=true
An extensive example of using Bloom Filters can be found at
accumulo/docs/examples/README.bloom .
Iterators
Iterators provide a modular mechanism for adding functionality to be executed by TabletServers when scanning or compacting data. This allows users to efficiently summarize, filter, and aggregate data. In fact, the built-in features of cell-level security and column fetching are implemented using Iterators. Some useful Iterators are provided with Accumulo and can be found in the org.apache.accumulo.core.iterators.user package.
Setting Iterators via the Shell
usage: setiter [-?] -ageoff | -agg | -class <name> | -regex |
-reqvis | -vers [-majc] [-minc] [-n <itername>] -p <pri>
[-scan] [-t <table>]
user@myinstance mytable> setiter -t mytable -scan -p 10 -n myiter
Setting Iterators Programmatically
scanner.addIterator(new IteratorSetting(
15, // priority
"myiter", // name this iterator
"com.company.MyIterator" // class name
));
Some iterators take additional parameters from client code, as in the following example:
IteratorSetting iter = new IteratorSetting(...);
iter.addOption("myoptionname", "myoptionvalue");
scanner.addIterator(iter)
Tables support separate Iterator settings to be applied at scan time, upon minor compaction and upon major compaction. For most uses, tables will have identical iterator settings for all three to avoid inconsistent results.
Versioning Iterators and Timestamps
Accumulo provides the capability to manage versioned data through the use of timestamps within the Key. If a timestamp is not specified in the key created by the client then the system will set the timestamp to the current time. Two keys with identical rowIDs and columns but different timestamps are considered two versions of the same key. If two inserts are made into accumulo with the same rowID, column, and timestamp, then the behavior is non-deterministic.
Timestamps are sorted in descending order, so the most recent data comes first. Accumulo can be configured to return the top k versions, or versions later than a given date. The default is to return the one most recent version.
The version policy can be changed by changing the VersioningIterator options for a table as follows:
user@myinstance mytable> config -t mytable -s
table.iterator.scan.vers.opt.maxVersions=3
user@myinstance mytable> config -t mytable -s
table.iterator.minc.vers.opt.maxVersions=3
user@myinstance mytable> config -t mytable -s
table.iterator.majc.vers.opt.maxVersions=3
Logical Time
Accumulo 1.2 introduces the concept of logical time. This ensures that timestamps set by accumulo always move forward. This helps avoid problems caused by TabletServers that have different time settings. The per tablet counter gives unique one up time stamps on a per mutation basis. When using time in milliseconds, if two things arrive within the same millisecond then both receive the same timestamp. When using time in milliseconds, accumulo set times will still always move forward and never backwards.
A table can be configured to use logical timestamps at creation time as follows:
user@myinstance> createtable -tl logical
Deletes
Deletes are special keys in accumulo that get sorted along will all the other data. When a delete key is inserted, accumulo will not show anything that has a timestamp less than or equal to the delete key. During major compaction, any keys older than a delete key are omitted from the new file created, and the omitted keys are removed from disk as part of the regular garbage collection process.
Filters
When scanning over a set of key-value pairs it is possible to apply an arbitrary filtering policy through the use of a Filter. Filters are types of iterators that return only key-value pairs that satisfy the filter logic. Accumulo has a few built-in filters that can be configured on any table: AgeOff, ColumnAgeOff, Timestamp, NoVis, and RegEx. More can be added by writing a Java class that extends the
org.apache.accumulo.core.iterators.Filter class.
The AgeOff filter can be configured to remove data older than a certain date or a fixed amount of time from the present. The following example sets a table to delete everything inserted over 30 seconds ago:
user@myinstance> createtable filtertest
user@myinstance filtertest> setiter -t filtertest -scan -minc -majc -p 10 -n myfilter -ageoff
AgeOffFilter removes entries with timestamps more than <ttl> milliseconds old
----------> set org.apache.accumulo.core.iterators.user.AgeOffFilter parameter negate, default false keeps k/v that pass accept method, true rejects k/v that pass accept method:
----------> set org.apache.accumulo.core.iterators.user.AgeOffFilter parameter ttl, time to live (milliseconds): 3000
----------> set org.apache.accumulo.core.iterators.user.AgeOffFilter parameter currentTime, if set, use the given value as the absolute time in milliseconds as the current time of day:
user@myinstance filtertest>
user@myinstance filtertest> scan
user@myinstance filtertest> insert foo a b c
user@myinstance filtertest> scan
foo a:b [] c
user@myinstance filtertest> sleep 4
user@myinstance filtertest> scan
user@myinstance filtertest>
To see the iterator settings for a table, use:
user@example filtertest> config -t filtertest -f iterator
---------+---------------------------------------------+------------------
SCOPE | NAME | VALUE
---------+---------------------------------------------+------------------
table | table.iterator.majc.myfilter .............. | 10,org.apache.accumulo.core.iterators.user.AgeOffFilter
table | table.iterator.majc.myfilter.opt.ttl ...... | 3000
table | table.iterator.majc.vers .................. | 20,org.apache.accumulo.core.iterators.VersioningIterator
table | table.iterator.majc.vers.opt.maxVersions .. | 1
table | table.iterator.minc.myfilter .............. | 10,org.apache.accumulo.core.iterators.user.AgeOffFilter
table | table.iterator.minc.myfilter.opt.ttl ...... | 3000
table | table.iterator.minc.vers .................. | 20,org.apache.accumulo.core.iterators.VersioningIterator
table | table.iterator.minc.vers.opt.maxVersions .. | 1
table | table.iterator.scan.myfilter .............. | 10,org.apache.accumulo.core.iterators.user.AgeOffFilter
table | table.iterator.scan.myfilter.opt.ttl ...... | 3000
table | table.iterator.scan.vers .................. | 20,org.apache.accumulo.core.iterators.VersioningIterator
table | table.iterator.scan.vers.opt.maxVersions .. | 1
---------+------------------------------------------+------------------
Combiners
Accumulo allows Combiners to be configured on tables and column families. When a Combiner is set it is applied across the values associated with any keys that share rowID, column family, and column qualifier. This is similar to the reduce step in MapReduce, which applied some function to all the values associated with a particular key.
For example, if a summing combiner were configured on a table and the following mutations were inserted:
Row Family Qualifier Timestamp Value
rowID1 colfA colqA 20100101 1
rowID1 colfA colqA 20100102 1
The table would reflect only one aggregate value:
rowID1 colfA colqA - 2
Combiners can be enabled for a table using the setiter command in the shell. Below is an example.
root@a14 perDayCounts> setiter -t perDayCounts -p 10 -scan -minc -majc -n daycount
-class org.apache.accumulo.core.iterators.user.SummingCombiner
TypedValueCombiner can interpret Values as a variety of number encodings
(VLong, Long, or String) before combining
----------> set SummingCombiner parameter columns,
<col fam>[:<col qual>]{,<col fam>[:<col qual>]} : day
----------> set SummingCombiner parameter type, <VARNUM|LONG|STRING>: STRING
root@a14 perDayCounts> insert foo day 20080101 1
root@a14 perDayCounts> insert foo day 20080101 1
root@a14 perDayCounts> insert foo day 20080103 1
root@a14 perDayCounts> insert bar day 20080101 1
root@a14 perDayCounts> insert bar day 20080101 1
root@a14 perDayCounts> scan
bar day:20080101 [] 2
foo day:20080101 [] 2
foo day:20080103 [] 1
Accumulo includes some useful Combiners out of the box. To find these look in the
org.apache.accumulo.core.iterators.user package.
Additional Combiners can be added by creating a Java class that extends
org.apache.accumulo.core.iterators.Combiner and adding a jar containing that class to Accumulo’s lib/ext directory.
An example of a Combiner can be found under
accumulo/src/examples/simple/main/java/org/apache/accumulo/examples/simple/combiner/StatsCombiner.java
Block Cache
In order to increase throughput of commonly accessed entries, Accumulo employs a block cache. This block cache buffers data in memory so that it doesn’t have to be read off of disk. The RFile format that Accumulo prefers is a mix of index blocks and data blocks, where the index blocks are used to find the appropriate data blocks. Typical queries to Accumulo result in a binary search over several index blocks followed by a linear scan of one or more data blocks.
The block cache can be configured on a per-table basis, and all tablets hosted on a tablet server share a single resource pool. To configure the size of the tablet server’s block cache, set the following properties:
tserver.cache.data.size: Specifies the size of the cache for file data blocks.
tserver.cache.index.size: Specifies the size of the cache for file indices.
To enable the block cache for your table, set the following properties:
table.cache.block.enable: Determines whether file (data) block cache is enabled.
table.cache.index.enable: Determines whether index cache is enabled.
The block cache can have a significant effect on alleviating hot spots, as well as reducing query latency. It is enabled by default for the !METADATA table.
Compaction
As data is written to Accumulo it is buffered in memory. The data buffered in memory is eventually written to HDFS on a per tablet basis. Files can also be added to tablets directly by bulk import. In the background tablet servers run major compactions to merge multiple files into one. The tablet server has to decide which tablets to compact and which files within a tablet to compact. This decision is made using the compaction ratio, which is configurable on a per table basis. To configure this ratio modify the following property:
table.compaction.major.ratio
Increasing this ratio will result in more files per tablet and less compaction work. More files per tablet means more higher query latency. So adjusting this ratio is a trade off between ingest and query performance. The ratio defaults to 3.
The way the ratio works is that a set of files is compacted into one file if the sum of the sizes of the files in the set is larger than the ratio multiplied by the size of the largest file in the set. If this is not true for the set of all files in a tablet, the largest file is removed from consideration, and the remaining files are considered for compaction. This is repeated until a compaction is triggered or there are no files left to consider.
The number of background threads tablet servers use to run major compactions is configurable. To configure this modify the following property:
tserver.compaction.major.concurrent.max
Also, the number of threads tablet servers use for minor compactions is configurable. To configure this modify the following property:
tserver.compaction.minor.concurrent.max
The numbers of minor and major compactions running and queued is visible on the Accumulo monitor page. This allows you to see if compactions are backing up and adjustments to the above settings are needed. When adjusting the number of threads available for compactions, consider the number of cores and other tasks running on the nodes such as maps and reduces.
If major compactions are not keeping up, then the number of files per tablet will grow to a point such that query performance starts to suffer. One way to handle this situation is to increase the compaction ratio. For example, if the compaction ratio were set to 1, then every new file added to a tablet by minor compaction would immediately queue the tablet for major compaction. So if a tablet has a 200M file and minor compaction writes a 1M file, then the major compaction will attempt to merge the 200M and 1M file. If the tablet server has lots of tablets trying to do this sort of thing, then major compactions will back up and the number of files per tablet will start to grow, assuming data is being continuously written. Increasing the compaction ratio will alleviate backups by lowering the amount of major compaction work that needs to be done.
Another option to deal with the files per tablet growing too large is to adjust the following property:
table.file.max
When a tablet reaches this number of files and needs to flush its in-memory data to disk, it will choose to do a merging minor compaction. A merging minor compaction will merge the tablet’s smallest file with the data in memory at minor compaction time. Therefore the number of files will not grow beyond this limit. This will make minor compactions take longer, which will cause ingest performance to decrease. This can cause ingest to slow down until major compactions have enough time to catch up. When adjusting this property, also consider adjusting the compaction ratio. Ideally, merging minor compactions never need to occur and major compactions will keep up. It is possible to configure the file max and compaction ratio such that only merging minor compactions occur and major compactions never occur. This should be avoided because doing only merging minor compactions causes 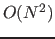 work to be done. The amount of work done by major compactions is ![$O(N\log_R(N))$]20 where *R is the compaction ratio.
work to be done. The amount of work done by major compactions is ![$O(N\log_R(N))$]20 where *R is the compaction ratio.
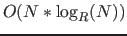{kind=link}
Compactions can be initiated manually for a table. To initiate a minor compaction, use the flush command in the shell. To initiate a major compaction, use the compact command in the shell. The compact command will compact all tablets in a table to one file. Even tablets with one file are compacted. This is useful for the case where a major compaction filter is configured for a table. In 1.4 the ability to compact a range of a table was added. To use this feature specify start and stop rows for the compact command. This will only compact tablets that overlap the given row range.
Pre-splitting tables
Accumulo will balance and distribute tables accross servers. Before a table gets large, it will be maintained as a single tablet on a single server. This limits the speed at which data can be added or queried to the speed of a single node. To improve performance when the a table is new, or small, you can add split points and generate new tablets.
In the shell:
root@myinstance> createtable newTable
root@myinstance> addsplits -t newTable g n t
This will create a new table with 4 tablets. The table will be split on the letters g'',n’’, and ``t’’ which will work nicely if the row data start with lower-case alphabetic characters. If your row data includes binary information or numeric information, or if the distribution of the row information is not flat, then you would pick different split points. Now ingest and query can proceed on 4 nodes which can improve performance.
Merging tablets
Over time, a table can get very large, so large that it has hundreds of thousands of split points. Once there are enough tablets to spread a table across the entire cluster, additional splits may not improve performance, and may create unnecessary bookkeeping. The distribution of data may change over time. For example, if row data contains date information, and data is continually added and removed to maintain a window of current information, tablets for older rows may be empty.
Accumulo supports tablet merging, which can be used to reduce delete the number of split points. The following command will merge all rows from A'' toZ’’ into a single tablet:
root@myinstance> merge -t myTable -s A -e Z
If the result of a merge produces a tablet that is larger than the configured split size, the tablet may be split by the tablet server. Be sure to increase your tablet size prior to any merges if the goal is to have larger tablets:
root@myinstance> config -t myTable -s table.split.threshold=2G
In order to merge small tablets, you can ask accumulo to merge sections of a table smaller than a given size.
root@myinstance> merge -t myTable -s 100M
By default, small tablets will not be merged into tablets that are already larger than the given size. This can leave isolated small tablets. To force small tablets to be merged into larger tablets use the ``-force’’ option:
root@myinstance> merge -t myTable -s 100M --force
Merging away small tablets works on one section at a time. If your table contains many sections of small split points, or you are attempting to change the split size of the entire table, it will be faster to set the split point and merge the entire table:
root@myinstance> config -t myTable -s table.split.threshold=256M
root@myinstance> merge -t myTable
Delete Range
Consider an indexing scheme that uses date information in each row. For example ``20110823-15:20:25.013’’ might be a row that specifies a date and time. In some cases, we might like to delete rows based on this date, say to remove all the data older than the current year. Accumulo supports a delete range operation which can efficiently removes data between two rows. For example:
root@myinstance> deleterange -t myTable -s 2010 -e 2011
This will delete all rows starting with 2010'' and it will stop at any row starting2011’’. You can delete any data prior to 2011 with:
root@myinstance> deleterange -t myTable -e 2011 --force
The shell will not allow you to delete an unbounded range (no start) unless you provide the ``-force’’ option.
Range deletion is implemented using splits at the given start/end positions, and will affect the number of splits in the table.
Cloning Tables
A new table can be created that points to an existing table’s data. This is a very quick metadata operation, no data is actually copied. The cloned table and the source table can change independently after the clone operation. One use case for this feature is testing. For example to test a new filtering iterator, clone the table, add the filter to the clone, and force a major compaction. To perform a test on less data, clone a table and then use delete range to efficiently remove a lot of data from the clone. Another use case is generating a snapshot to guard against human error. To create a snapshot, clone a table and then disable write permissions on the clone.
The clone operation will point to the source table’s files. This is why the flush option is present and is enabled by default in the shell. If the flush option is not enabled, then any data the source table currently has in memory will not exist in the clone.
A cloned table copies the configuration of the source table. However the permissions of the source table are not copied to the clone. After a clone is created, only the user that created the clone can read and write to it.
In the following example we see that data inserted after the clone operation is not visible in the clone.
root@a14> createtable people
root@a14 people> insert 890435 name last Doe
root@a14 people> insert 890435 name first John
root@a14 people> clonetable people test
root@a14 people> insert 890436 name first Jane
root@a14 people> insert 890436 name last Doe
root@a14 people> scan
890435 name:first [] John
890435 name:last [] Doe
890436 name:first [] Jane
890436 name:last [] Doe
root@a14 people> table test
root@a14 test> scan
890435 name:first [] John
890435 name:last [] Doe
root@a14 test>
The du command in the shell shows how much space a table is using in HDFS. This command can also show how much overlapping space two cloned tables have in HDFS. In the example below du shows table ci is using 428M. Then ci is cloned to cic and du shows that both tables share 428M. After three entries are inserted into cic and its flushed, du shows the two tables still share 428M but cic has 226 bytes to itself. Finally, table cic is compacted and then du shows that each table uses 428M.
root@a14> du ci
428,482,573 [ci]
root@a14> clonetable ci cic
root@a14> du ci cic
428,482,573 [ci, cic]
root@a14> table cic
root@a14 cic> insert r1 cf1 cq1 v1
root@a14 cic> insert r1 cf1 cq2 v2
root@a14 cic> insert r1 cf1 cq3 v3
root@a14 cic> flush -t cic -w
27 15:00:13,908 [shell.Shell] INFO : Flush of table cic completed.
root@a14 cic> du ci cic
428,482,573 [ci, cic]
226 [cic]
root@a14 cic> compact -t cic -w
27 15:00:35,871 [shell.Shell] INFO : Compacting table ...
27 15:03:03,303 [shell.Shell] INFO : Compaction of table cic completed for given range
root@a14 cic> du ci cic
428,482,573 [ci]
428,482,612 [cic]
root@a14 cic>
** Next:** Table Design ** Up:** Apache Accumulo User Manual Version 1.4 ** Previous:** Development Clients ** Contents**