Ranges and Splits
Accumulo Tour: Ranges and Splits
Tour page 8 of 13
A Range is a specified group of Keys. There are many ways to create a Range. Here are a few examples:
Range r1 = new Range(startKey, endKey); // Creates a range from startKey inclusive to endKey inclusive.
Range r2 = new Range(row); // Creates a range that covers an entire row.
Range r3 = new Range(startRow, endRow); // Creates a range from startRow inclusive to endRow inclusive.
A Scanner by default will scan all Key’s in a table but this can be inefficient. It is a good practice to
set a range on a Scanner.
scanner.setRange(new Range("id0000", "id0010")); // returns rows from id0000 to id0010
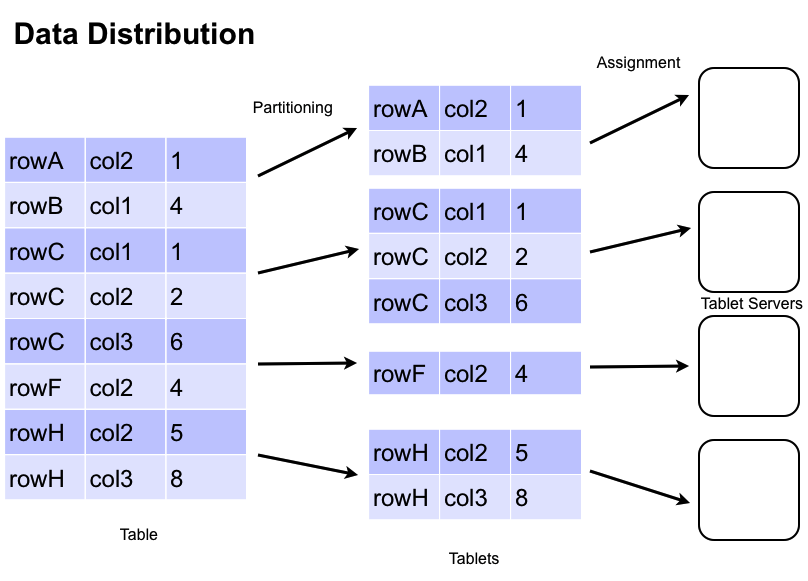
As your data grows larger, Accumulo will split tables into smaller pieces called Tablet’s which can
be distributed across multiple Tablet Servers. By default, a table will get split into Tablets on
row boundaries, guaranteeing an entire row will be on one Tablet Server. We have the ability to
tell Accumulo where to split tables by setting split points. This is done using addSplits in the
TableOperations API. The image below demonstrates how Accumulo splits data.
Take a minute to learn these Accumulo terms:
| Tablet | A partition of a table |
| Split | A point where tables are partitioned into separate tablets |
| Flush | Action taken when data is written from memory to disk |
| Compact | Action taken when files on disk are consolidated |
| Iterator | A server side mechanism that can filter and modify Key/Value pairs |
Knowing these terms are critical when working closely with Accumulo. Iterators are especially unique and powerful. More on them later.
When working with large amounts of data across many ‘Tablet Server’s, a simple Scanner might not do the trick.
Next lesson we learn about the power of the multithreaded BatchScanner!