Replicating data across Accumulo clusters
Author: Josh Elser
Date: 06 Apr 2015
Originally posted at https://blogs.apache.org/accumulo/entry/data_center_replication
Traditionally, Apache Accumulo can only operate within the confines of a single physical location. The primary reason for this restriction is that Accumulo relies heavily on Apache ZooKeeper for distributed lock management and some distributed state. Due to the consistent nature of ZooKeeper and its protocol, it doesn’t handle wide-area networks (WAN) well. As such, Accumulo suffers the same problems operating over a WAN.
Data-Center Replication is a new feature, to be included in the upcoming Apache Accumulo 1.7.0, which aims to address the limitation of Accumulo to one local-area network (LAN). The implementation makes a number of decisions with respect to consistency and available which aim to avoid the normal “local” operations of the primary Accumulo instance. That is to say, replication was designed in such a way that enabling the feature on an instance should not affect the performance of that system. However, this comes at a cost of consistency across all replicas. Replication from one instance to others is performed lazily. Succinctly, replication in Accumulo can be described as an eventually-consistent system and not a strongly-consistent system (an Accumulo instance is strongly-consistent).
Because replication is performed lazily, this implies that the data to replicate must be persisted in some shape until the actual replication takes place. This is done using Accumulo’s write-ahead log (WAL) files for this purpose. The append-only nature of these files make them obvious candidates for reuse without the need to persist the data in another form for replication. The only necessary changes internally to Accumulo to support this is changing the conditions that the Accumulo garbage collector will delete WAL files. Using WAL files also has the benefit of making HDFS capacity the limiting factor in how “lazy” replication can be. This means that the amount of time replication can be offline or stalled is only limited by the amount of extra HDFS space available which is typically ample.
Terminology
Before getting into details on the feature, it will help to define some basic terminology. Data in Accumulo is replicated from a “primary” Accumulo instance to a “peer” Accumulo instance. Each instance here is a normal Accumulo instance – each instance is only differentiated by a few new configuration values. Users ingest data into the primary instance, and that data will eventually be replicated to a peer. Each instance requires a unique name to identify itself among all Accumulo instances replicating with each other. Replication from a primary to a peer is defined on a per-table basis – that is, the configuration states that tableA on the primary will be replicated to tableB on the peer. A primary can have multiple peers defined, e.g. tableA on the primary can will be replicated to tableB on peer1 and tableC on peer2. Overview
Internally, replication is comprised of a few components to make up the user-facing feature: the management of data ingested on the primary which needs to be replicated, the assignment of replication work within the primary, the execution of that work within the primary to send the data to a peer, and the application of the data to the appropriate table within the peer.
State Management on Primary
The most important state to manage for replication is the tracking the data that was ingested in the primary. This is what ensures that all of the data will be eventually replicated to the necessary peer(s). This state is kept in both the Accumulo metadata table and a new table in the accumulo namespace: replication. Through the use of an Accumulo Combiner on these tables, updates to the replication state are simple updates to the replication table. This makes management of the state machine across all of the nodes within the Accumulo instance extremely simple. For example, TabletServers reporting that data was ingested into a write-ahead log, the Master preparing data to be replicated and the TabletServer reporting that data has been replicated to the peer are all updates to the replication table.
To “seed” the state machine, TabletServers first write to the metadata table at the end of a minor compaction. The Master will read records from the metadata table and add them to the replication table. Each Key-Value pair in the replication table represents a WAL’s current state within the replication “state machine” with different column families representing different states. For example, one column family represents the status of a WAL file being replicated to a specific peer while a different column family represents the status of a WAL file being replicated to all necessary peers.
The Master is the primary driver of this state machine, reading the replication table and making the necessary updates repeatedly. This allows the Master to maintain a constant amount of memory with respect to the amount of data that needs to be replicated. The only limitation on persisted state for replication is the size of the replication table itself and the amount of space the WAL files on HDFS consume.
RPC from primary to peer
Like the other remote procedure calls in Accumulo, Apache Thrift is used to make RPCs from the primary Accumulo instance to a peer instance. The purpose of these methods is to send the relevant data from a WAL file to the peer. The Master advertises units of replication work, a WAL file that needs to be replicated to a single peer, and all TabletServers in the primary instance will try to reserve, and then perform, that work. ZooKeeper provides this feature to us with very little code in Accumulo.
Once a TabletServer obtains the work, it will read through the WAL file extracting updates only for the table in this unit of work and send the updates across the wire to a TabletServer in the peer. The TabletServer on the primary asks the active Master in the peer for a TabletServer to communicate with. As such, ignoring some very quick interactions with the Master, RPC for replication is primarily a TabletServer to TabletServer operation which means that replication should scale in performance with respect to the number of available TabletServers on the primary and peer.
The amount of data read from a WAL and sent to the peer per RPC is a configurable parameter defaulting to 50MB. Increasing the amount of data read at a time will have a large impact on the amount of memory consumed by a TabletServer when using replication, so take care when altering this property. It is also important to note that the Thrift server used for the purposes of replication is completely separate from the thrift server used by clients. Replication and the client service servers will not compete against one another for RPC resources.
Replay of data on peer
After a TabletServer on the primary invokes an RPC to a TabletServer on the peer, but before that RPC completes, the TabletServer on the peer must apply the updates it received to the local table. The TabletServer on the peer constructs a BatchWriter and simply applies the updates to the table. In the event of an error in writing the data, the RPC will return in error and it will be retried by a TabletServer on the primary. As such, in these failure conditions, it is possible that data will be applied on the peer multiple times. The use of Accumulo Combiners on tables used being replicated is nearly always a bad idea which will result in inconsistencies between the primary and replica.
Because there are many TabletServers, each with their own BatchWriter, potential throughput for replication on the peer should be equivalent to the ingest throughput observed by clients normally ingesting data uniformly into Accumulo.
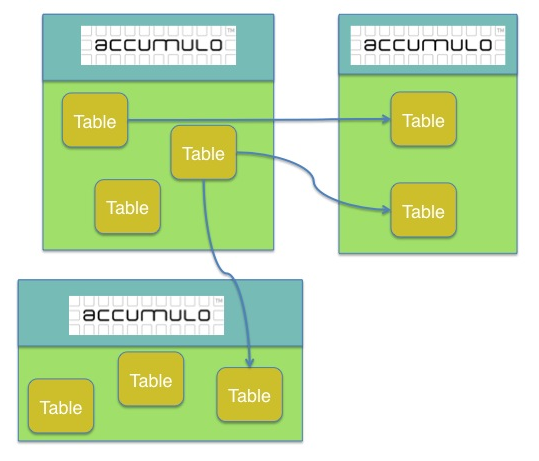
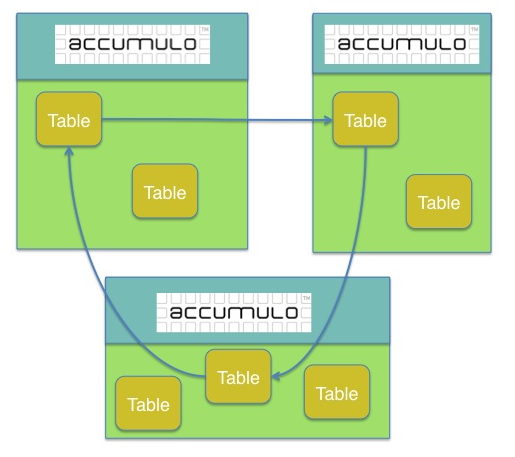
Complex replication configurations
So far, we’ve only touched on configurations which have a single primary and one to many peers; however, the feature allows multiple primary instances in addition to multiple peers. This primary-primary configuration allows data to be replicated in both directions instead of just one. This can be extended even further to allow replication between a trio of instances: primaryA replicates to primaryB which replicates to primaryC which replicates to primaryA. This aspect is supported by including provenance of which systems an update was seen inside of each Mutation. In “cyclic” replication setups, this prevents updates from being replicated indefinitely.
Supporting these cycles allows for different collections of users to access physically separated instances and eventually see the changes made by other groups. For example, consider two instance of Accumulo, one in New York City and another San Francisco. Users on the west coast can use the San Francisco instance while users on the east coast can use the instance in New York. With the two instances configured to replicate to each other, data created by east coast users will eventually be seen by west coast users and vice versa.
Conclusion and future work
The addition of the replication feature fills a large gap in the architecture of Accumulo where the system does not easily operate across WANs. While strong consistency between a primary and a peer is sacrificed, the common case of using replication for disaster recovery favors availability of the system over strong consistency and has the added benefit of not significantly impacting the ingest performance on the primary instance. Replication provides active backup support while enabling Accumulo to automatically share data between instances across large physical distances.
One interesting detail about the implementation of this feature is that the code which performs replication between two Accumulo instances, the AccumuloReplicaSystem, is pluggable via the ReplicaSystem interface. It is reasonable to consider other implementations which can automatically replicate data from Accumulo to other systems for purposes of backup or additional query functionality through other data management systems. For example, Accumulo could be used to automatically replicate data to other indexing systems such as Lucene or even relational databases for advanced query functionality. Certain implementations of the ReplicaSystem could perform special filtering to limit the set of columns replicated to certain systems resulting in a subset of the complete dataset stored in one Accumulo instance without forcing clients to write the data to multiple systems. Each of these considerations are only theoretical at this point; however, the potential for advancement is definitely worth investigating.
View all posts in the news archive